Planet to planet low-thrust#
In this tutorial we show the use of the pykep.trajopt.sf_pl2pl to find a low-thrust trajectory connecting two moving planets.
The decision vector for this class, compatible with pygmo [BI20] UDPs (User Defined Problems), is:
containing the starting epoch \(t_0\) as a MJD2000, the final mass \(m_f\) as well as the starting and final \(V^{\infty}\), throttles and the time-of-flight \(T_{tof}\).
Note
This notebook makes use of the commercial solver SNOPT 7 and to run needs a valid snopt_7_c library installed in the system. In case SNOPT7 is not available, you can still run the notebook using, for example uda = pg.algorithm.nlopt("slsqp") with minor modifications.
Basic imports:
import pykep as pk
import numpy as np
import time
import pygmo as pg
import pygmo_plugins_nonfree as ppnf
import time
from matplotlib import pyplot as plt
We start defining the problem data.
# Problem data
mu = pk.MU_SUN
max_thrust = 0.6
isp = 3000
veff = isp * pk.G0
# Source and destination planets
earth = pk.planet_to_keplerian(
pk.planet(pk.udpla.jpl_lp(body="EARTH")), when=pk.epoch(5000)
)
mars = pk.planet_to_keplerian(
pk.planet(pk.udpla.jpl_lp(body="MARS")), when=pk.epoch(5000)
)
venus = pk.planet_to_keplerian(
pk.planet(pk.udpla.jpl_lp(body="venus")), when=pk.epoch(5000)
)
# Initial state
ms = 1500.0
# Number of segments
nseg = 30
We here instantiate two different versions of the same UDP (User Defined Problem), with analytical gradients and without.
For the purpose of this simple notebook we choose a relatively simple Earth to Mars transfer with an initial \(V_{\infty}\) of 3 km/s.
udp_nog = pk.trajopt.sf_pl2pl(
pls=earth,
plf=mars,
ms=ms,
mu=pk.MU_SUN,
max_thrust=max_thrust,
veff=veff,
t0_bounds=[7360, 8300.0],
tof_bounds=[100.0, 350.0],
mf_bounds=[1000., ms],
vinfs=0.,
vinff=0.,
nseg=nseg,
cut=0.6,
mass_scaling=ms,
r_scaling=pk.AU,
v_scaling=pk.EARTH_VELOCITY,
with_gradient=False,
)
udp_g = pk.trajopt.sf_pl2pl(
pls=earth,
plf=mars,
ms=ms,
mu=pk.MU_SUN,
max_thrust=max_thrust,
veff=veff,
t0_bounds=[7360, 8300.0],
tof_bounds=[100.0, 350.0],
mf_bounds=[1000., ms],
vinfs=0.,
vinff=0.,
nseg=nseg,
cut=0.6,
mass_scaling=ms,
r_scaling=pk.AU,
v_scaling=pk.EARTH_VELOCITY,
with_gradient=True,
)
Analytical performances of the analytical gradient#
And we take a quick look at the performances of the analytical gradient with respect to the numerically computed one.
# We need to generste a random chromosomes compatible with the UDP where to test the gradient.
prob_g = pg.problem(udp_g)
pop_g = pg.population(prob_g, 1)
First the analytical gradient:
%%timeit
udp_g.gradient(pop_g.champion_x)
388 μs ± 10.3 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Then a simple numerical gradient based on finite differences:
%%timeit
pg.estimate_gradient(udp_g.fitness, pop_g.champion_x)
4.84 ms ± 50.3 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Then a higher order numerical gradient:
%%timeit
pg.estimate_gradient_h(udp_g.fitness, pop_g.champion_x)
14.4 ms ± 48.6 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
The analytical gradient its exact and faster, seems like a no brainer to use it.
In reality, the effects on the optimization technique used are not straightforward, making the option to use numerical gradients still interesting in some, albeit rare, cases.
Solving the low-thrust transfer#
We define (again) the optimization problem, and set a tolerance for pagmo to be able to judge the relative value of two individuals.
Note
This tolerance has a different role from the numerical tolerance set in the particular algorithm chosen to solve the problem and is only used by the pagmo machinery to decide outside the optimizer whether the new proposed indivdual is better than what was the previous champion.
prob_g = pg.problem(udp_g)
prob_g.c_tol = 1e-6
… and we define an optimization algorithm.
snopt72 = "/Users/dario.izzo/opt/libsnopt7_c.dylib"
uda = ppnf.snopt7(library=snopt72, minor_version=2, screen_output=False)
uda.set_integer_option("Major iterations limit", 2000)
uda.set_integer_option("Iterations limit", 20000)
uda.set_numeric_option("Major optimality tolerance", 1e-3)
uda.set_numeric_option("Major feasibility tolerance", 1e-11)
#uda = pg.nlopt("slsqp")
algo = pg.algorithm(uda)
We solve the problem from random initial guess ten times and only save the result if a feasible solution is found (as defined by the criterias above)
masses = []
xs = []
for i in range(10):
pop_g = pg.population(prob_g, 1)
pop_g = algo.evolve(pop_g)
if(prob_g.feasibility_f(pop_g.champion_f)):
print(".", end="")
masses.append(pop_g.champion_x[1])
xs.append(pop_g.champion_x)
else:
print("x", end ="")
print("\nBest mass is: ", np.max(masses))
print("Worst mass is: ", np.min(masses))
best_idx = np.argmax(masses)
.x...x.x..
Best mass is: 1234.15683652
Worst mass is: 1000.00240866
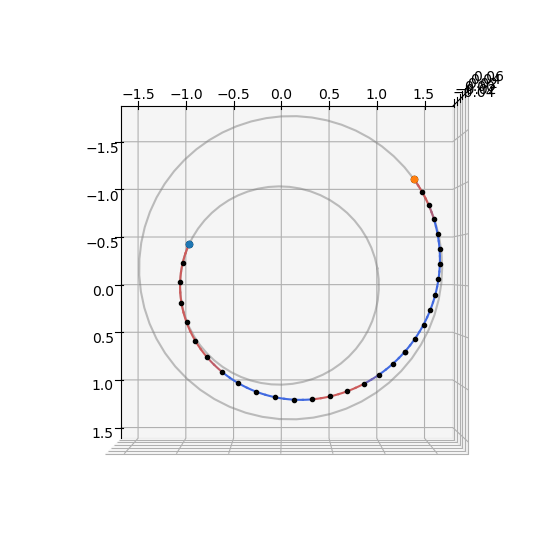
And we plot the trajectory found:
udp_g.pretty(xs[best_idx])
Low-thrust NEP transfer
Departure: earth(jpl_lp)(K)
Arrival: mars(jpl_lp)(K)
Launch epoch: 7451.99905 MJD2000, a.k.a. 2020-05-26T23:58:37.777239
Arrival epoch: 7801.99905 MJD2000, a.k.a. 2021-05-11T23:58:37.777239
Time of flight (days): 350.00000
Launch DV (km/s) 0.00000000 - [-0.0,-0.0,-0.0]
Arrival DV (km/s) 0.00000000 - [-0.0,-0.0,-0.0]
Final mass (kg): 1234.1568365174858
Details on the low-thrust leg:
Number of segments: 30
Number of fwd segments: 18
Number of bck segments: 12
Maximum thrust: 0.6
Central body gravitational parameter: 1.3271244004127942e+20
Specific impulse: 29419.949999999997
Time of flight: 30240000
Initial mass: 1500
Final mass: 1234.1568365174858
State at departure: [[-61940343629.2697, -138342786962.2452, 4315832.209158619], [26703.174217445237, -12284.734893133622, 0.38324263734277736]]
State at arrival: [[-154574671931.75818, 191750935543.9109, 7812362370.575885], [-17947.983008640604, -13143.524741070263, 165.21826805857714]]
Throttles values: [0.9149919539929579, -0.2725359209100713, -0.29751285015299656, 0.962467223571917, -0.10214778572097537, -0.25144119278969174, 0.9776102300781263, 0.0761024016853803, -0.19618017885672326, 0.9577082586238517, 0.25533303803466817, -0.13266475948495784, 0.9020227810244762, 0.4270404077693045, -0.06317747015340268, 0.8124941812081083, 0.5828797608824411, 0.010217150887220914, 0.6258910897305112, 0.6441274653944074, 0.07604724328788541, 8.643112090963488e-06, 1.2971573089761085e-05, 2.02573959082645e-06, 1.9402676195389745e-06, 4.116571390270388e-06, 1.0918826610204628e-06, 1.7531486204076886e-06, 6.6492515764816175e-06, 2.0439159913518445e-06, 6.497048168817056e-06, 6.254154897918531e-05, 2.222633512201523e-05, -3.907433113104457e-05, 0.0005705546606046523, 0.00023585797399559014, -0.1980851209765093, 0.8898566605361083, 0.40849620097319755, -0.3261733750073858, 0.8402697810771312, 0.4330792360402391, -0.44216210010572304, 0.7765577216795246, 0.4488326890553638, -0.16827487274493602, 0.21634099070250623, 0.14069169750160235, -0.00028083636215234757, 0.00027196352431085234, 0.00020171101827332145, -6.755298505147713e-07, 4.901379402024183e-07, 4.368915123034922e-07, -3.224169200091259e-06, 1.5455028409302713e-06, 1.7622592268945932e-06, -5.128303061091521e-06, 1.8289984300969872e-06, 2.5613455275741694e-06, -1.201177884483597e-06, 2.4358299399221113e-07, 6.745275326332689e-07, -7.32175825082655e-07, 1.1147397752068074e-07, 4.2811046712246406e-07, -1.4768666477965314e-06, -3.741517913801966e-08, 5.316783969739916e-07, -2.822836736482606e-06, -6.205060557090042e-07, 7.994338305580654e-07, -8.907902552019307e-06, -1.6478656337137234e-06, 2.1705592125269153e-06, -7.391982864209063e-06, -2.372687553706626e-06, 1.530148390821635e-06, -8.090054508720513e-07, -2.8958416763596854e-07, 7.234658896056569e-08, -0.6702759079241221, -0.3770492971452008, 0.0754920979561721, -0.8177587262868643, -0.5735537329417719, 0.0480289692781687, -0.7588285984053121, -0.6512901333686354, -0.0005674653604181771]
Mismatch constraints: [0.94464111328125, 6.167388916015625, 3.928389072418213, 2.843007678166032e-07, 2.4610253603896126e-06, 9.204180742017343e-07, -3.0061348752496997e-06]
Throttle constraints: [6.431122301364667e-11, 9.435785486289205e-12, 7.194600470938894e-11, 7.3575454617724745e-09, 8.988809696575117e-11, 3.156583883168196e-10, -0.1875769689088429, -0.9999999997529313, -0.999999999978097, -0.9999999999485363, -0.9999999955523331, -0.999999617311592, -0.002048262337711937, 2.4431590084361687e-10, 6.346663194989333e-10, -0.9050859891986514, -0.9999998064794442, -0.9999999999991126, -0.9999999999841106, -0.9999999999637947, -0.9999999999980429, -0.9999999999992683, -0.9999999999975347, -0.9999999999910074, -0.9999999999132225, -0.9999999999373876, -0.9999999999992564, -0.40286497792497955, 8.796792183574098e-10, 1.5980405887461302e-09]
ax = udp_g.plot(xs[best_idx], show_gridpoints=True)
ax.view_init(90, 0)
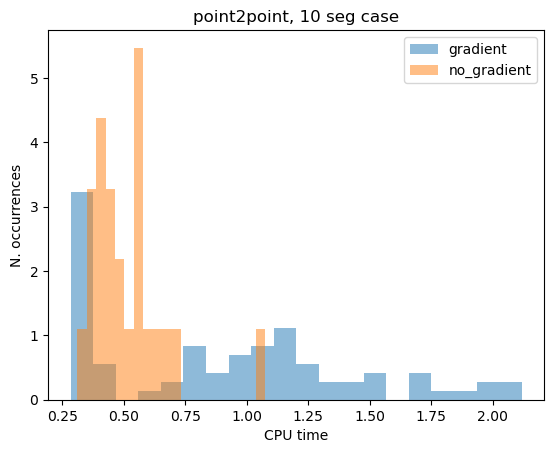
Graident vs no gradient#
We here take a look at the difference in solving the problem using the analytical gradient and not using it. To do so we solve the same problem starting from 100 different initial guesses using both versions and compare.
from tqdm import tqdm
cpu_nog = []
cpu_g = []
fail_g = 0
fail_nog = 0
prob_g = pg.problem(udp_g)
prob_nog = pg.problem(udp_nog)
prob_g.c_tol = 1e-6
prob_nog.c_tol = 1e-6
for i in tqdm(range(100)):
pop_g = pg.population(prob_g, 1)
pop_nog = pg.population(prob_nog)
pop_nog.push_back(pop_g.champion_x)
start = time.time()
pop_g = algo.evolve(pop_g)
end = time.time()
if not prob_g.feasibility_f(pop_g.champion_f):
fail_g += 1
else: # We only record the time for successfull attempts
cpu_g.append(end - start)
start = time.time()
pop_nog = algo.evolve(pop_nog)
end = time.time()
if not prob_nog.feasibility_f(pop_nog.champion_f):
fail_nog += 1
else: # We only record the time for successfull attempts
cpu_nog.append(end - start)
print(f"Gradient: {np.median(cpu_g):.4e}s")
print(f"No Gradient: {np.median(cpu_nog):.4e}s")
print(f"\nGradient (n.fails): {fail_g}")
print(f"No Gradient (n.fails): {fail_nog}")
100%|██████████| 100/100 [05:15<00:00, 3.16s/it]
Gradient: 1.0034e+00s
No Gradient: 1.9059e+00s
Gradient (n.fails): 13
No Gradient (n.fails): 46
cpu_g = np.array(cpu_g)
cpu_nog = np.array(cpu_nog)
plt.hist(cpu_g[cpu_g < 2.2], bins=20, label="gradient", density=True, alpha=0.5)
plt.hist(cpu_nog[cpu_nog < 1.2], bins=20, label="no_gradient", density=True, alpha=0.5)
# plt.xlim([0,0.15])
plt.legend()
plt.title("point2point, 10 seg case")
plt.xlabel("CPU time")
plt.ylabel("N. occurrences")
Text(0, 0.5, 'N. occurrences')